พื้นที่ที่ไม่มีการทำลาย
นิติบุคคลตัวอักษรทั่วไปที่ใช้ใน HTML คือพื้นที่ที่ไม่ทำให้หยุดนิ่ง: & nbsp;พื้นที่ที่ไม่ทำลายคือช่องว่างที่จะไม่บุกเข้าสู่เส้นใหม่
คำสองคำที่คั่นด้วยช่องว่างที่ไม่ทำลายจะยึดติดกัน (ไม่เข้าเส้นใหม่) นี่เป็นประโยชน์เมื่อทำลายคำพูดอาจเป็นอุปสรรค
ตัวอย่าง:
- § 10
- 10 กม. / ชม
- 22.00 น
การใช้พื้นที่ที่ไม่ทำลายอีกเพื่อป้องกันไม่ให้เบราว์เซอร์ตัดส่วนต่างๆในหน้า HTML
หากคุณเขียน 10 ช่องว่างในข้อความเบราว์เซอร์จะลบ 9 ช่องออกจากข้อความ หากต้องการเพิ่มช่องว่างจริงในข้อความของคุณคุณสามารถใช้ & nbsp; ตัวอักษร
เครื่องหมายยัติภังค์ที่ไม่ใช้งาน (-) ช่วยให้คุณสามารถใช้อักขระยัติภังค์ (-) ที่จะไม่ทำลาย
สัญลักษณ์ HTML
เอนทิตี HTML Symbol
เอนทิตี HTML ได้อธิบายไว้ในบทก่อนหน้าสัญลักษณ์ทางคณิตศาสตร์เทคนิคและสกุลเงินจำนวนมากไม่ปรากฏบนแป้นพิมพ์ปกติ
หากต้องการเพิ่มสัญลักษณ์ดังกล่าวลงในหน้า HTML คุณสามารถใช้ชื่อเอนทิตี HTML ได้
หากไม่มีชื่อเอนทิตีอยู่คุณสามารถใช้หมายเลขเอนทิตี, เลขทศนิยมหรือเลขฐานสิบหก
ทดลองกดตรงนี้
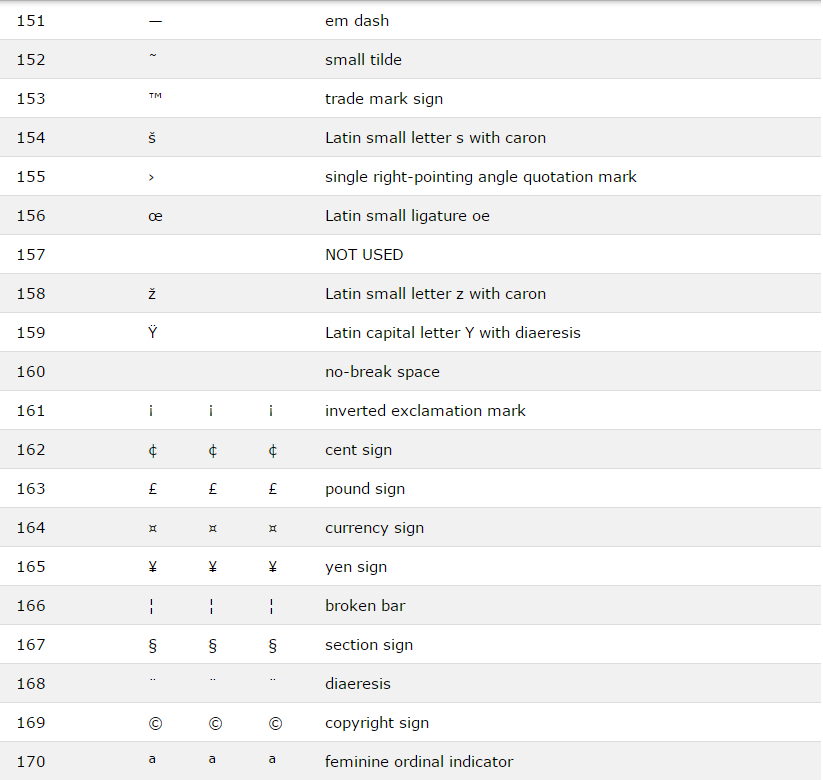
สัญลักษณ์ทางคณิตศาสตร์บางรูปแบบที่สนับสนุนโดย HTML

บางตัวอักษรกรีกที่สนับสนุนโดย HTML

บางเอนทิตีอื่นที่สนับสนุนโดย HTML

การเข้ารหัส HTML (ชุดอักขระ)
หากต้องการแสดงหน้า HTML อย่างถูกต้องเว็บเบราเซอร์จะต้องทราบว่าต้องใช้ชุดอักขระ (การเข้ารหัสอักขระ) ใดบ้าง
ANSI (Windows-1252) เป็นชุดอักขระ Windows ดั้งเดิมพร้อมด้วยรหัสอักขระ 256 ตัว
ISO-8859-1 เป็นชุดอักขระเริ่มต้นสำหรับ HTML 4 ชุดอักขระนี้ยังรองรับรหัสอักขระ 256 ตัว
เนื่องจาก ANSI และ ISO-8859-1 มีขีด จำกัด ดังนั้นการเข้ารหัสอักขระเริ่มต้นจึงเปลี่ยนเป็น UTF-8 ใน HTML5
UTF-8 (Unicode) ครอบคลุมเกือบทุกตัวอักษรและสัญลักษณ์ในโลก
โปรเซสเซอร์ HTML 4 ทั้งหมดยังสนับสนุนการเข้ารหัส UTF-8
ซึ่งระบุไว้ในแท็ก <meta>:
สำหรับ HTML4:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1">
สำหรับ HTML5:
<meta charset="UTF-8">
หากเบราเซอร์ตรวจพบ ISO-8859-1 ในเว็บเพจค่าเริ่มต้นจะเป็น ANSI เพราะ ANSI เหมือนกับ ISO-8859-1 ยกเว้น ANSI มีอักขระพิเศษ 32 ตัว
ตารางต่อไปนี้แสดงความแตกต่างระหว่างชุดอักขระที่อธิบายไว้ด้านบน:
การเข้ารหัสตัวอักษรคืออะไร?
ASCII เป็นมาตรฐานการเข้ารหัสตัวอักษรตัวแรก (หรือที่เรียกว่าชุดอักขระ) ASCII กำหนด 127 ตัวอักษรตัวเลขที่แตกต่างกันซึ่งสามารถใช้ได้บนอินเทอร์เน็ต: ตัวเลข (0-9), ตัวอักษรภาษาอังกฤษ (A-Z) และอักขระพิเศษบางอย่างเช่น! $ + - () @ <>ANSI (Windows-1252) เป็นชุดอักขระ Windows ดั้งเดิมพร้อมด้วยรหัสอักขระ 256 ตัว
ISO-8859-1 เป็นชุดอักขระเริ่มต้นสำหรับ HTML 4 ชุดอักขระนี้ยังรองรับรหัสอักขระ 256 ตัว
เนื่องจาก ANSI และ ISO-8859-1 มีขีด จำกัด ดังนั้นการเข้ารหัสอักขระเริ่มต้นจึงเปลี่ยนเป็น UTF-8 ใน HTML5
UTF-8 (Unicode) ครอบคลุมเกือบทุกตัวอักษรและสัญลักษณ์ในโลก
โปรเซสเซอร์ HTML 4 ทั้งหมดยังสนับสนุนการเข้ารหัส UTF-8
แอตทริบิวต์ charset HTML
ในการแสดงเพจ HTML อย่างถูกต้องเว็บเบราเซอร์ต้องรู้จักชุดอักขระที่ใช้ในเพจซึ่งระบุไว้ในแท็ก <meta>:
สำหรับ HTML4:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1">
สำหรับ HTML5:
<meta charset="UTF-8">
หากเบราเซอร์ตรวจพบ ISO-8859-1 ในเว็บเพจค่าเริ่มต้นจะเป็น ANSI เพราะ ANSI เหมือนกับ ISO-8859-1 ยกเว้น ANSI มีอักขระพิเศษ 32 ตัว
ความแตกต่างระหว่างชุดอักขระ
ตารางต่อไปนี้แสดงความแตกต่างระหว่างชุดอักขระที่อธิบายไว้ด้านบน:











ชุดอักขระ ASCII
ASCII ใช้ค่าจาก 0 ถึง 31 (และ 127) สำหรับอักขระควบคุม
ASCII ใช้ค่าจาก 32 ถึง 126 สำหรับตัวอักษรตัวเลขและสัญลักษณ์
ASCII ไม่ใช้ค่าจาก 128 ถึง 255
ชุดอักขระ ANSI (Windows-1252)
ANSI เหมือนกับ ASCII สำหรับค่าตั้งแต่ 0 ถึง 127
ANSI มีชุดอักขระที่เป็นกรรมสิทธิ์สำหรับค่าตั้งแต่ 128 ถึง 159
ANSI เหมือนกับ UTF-8 สำหรับค่าตั้งแต่ 160 ถึง 255
ชุดอักขระ ISO-8859-1
8859-1 เหมือนกับ ASCII สำหรับค่าตั้งแต่ 0 ถึง 127
8859-1 ไม่ใช้ค่าตั้งแต่ 128 ถึง 159
8859-1 เหมือนกับ UTF-8 สำหรับค่าตั้งแต่ 160 ถึง 255
ชุดอักขระ UTF-8
UTF-8 เหมือนกับ ASCII สำหรับค่าตั้งแต่ 0 ถึง 127
UTF-8 ไม่ใช้ค่าตั้งแต่ 128 ถึง 159
UTF-8 จะเหมือนกับ ANSI และ 8859-1 สำหรับค่าตั้งแต่ 160 ถึง 255
UTF-8 ยังคงมีค่า 256 โดยมีอักขระมากกว่า 10 000 ตัว
ให้ดูที่การอ้างอิงชุดอักขระ HTML ที่สมบูรณ์แบบของเรา
ที่ตั้งทรัพยากร HTML Uniform
❮ก่อนหน้าต่อไป❯
URL คือคำอื่นสำหรับที่อยู่เว็บ
URL สามารถประกอบด้วยคำ (w3schools.com) หรือที่อยู่ Internet Protocol (IP) (192.68.20.50)
คนส่วนใหญ่จะป้อนชื่อเมื่อท่องเนื่องจากชื่อง่ายกว่าตัวเลข
URL - Uniform Resource Locator
เว็บเบราเซอร์ร้องขอหน้าเว็บจากเว็บเซิร์ฟเวอร์โดยใช้ URL
Uniform Resource Locator (URL) ใช้เพื่อระบุเอกสาร (หรือข้อมูลอื่น ๆ ) บนเว็บ
ที่อยู่เว็บเช่น https://www.w3schools.com/html/default.asp ปฏิบัติตามกฎไวยากรณ์เหล่านี้:
scheme://prefix.domain:port/path/filename
คำอธิบาย:
- โครงการ - กำหนดประเภทของบริการอินเทอร์เน็ต (โดยทั่วไปคือ http หรือ https)
- คำนำหน้า - กำหนดคำนำหน้าโดเมน (ค่าเริ่มต้นสำหรับ http คือ www)
- โดเมน - กำหนดชื่อโดเมนอินเทอร์เน็ต (เช่น w3schools.com)
- พอร์ต - กำหนดหมายเลขพอร์ตที่โฮสต์ (ค่าเริ่มต้นสำหรับ http คือ 80)
- เส้นทาง - กำหนดเส้นทางที่เซิร์ฟเวอร์ (ถ้าละไว้: ไดเรกทอรีรากของไซต์)
- filename - กำหนดชื่อของเอกสารหรือทรัพยากร
Common URL Schemes
ตารางด้านล่างแสดงแผนภาพทั่วไปบางส่วน:

การเข้ารหัส URL
URL สามารถส่งผ่านทางอินเทอร์เน็ตโดยใช้ชุดอักขระ ASCII เท่านั้น หาก URL มีอักขระอยู่นอกชุด ASCII URL ต้องได้รับการแปลง
การเข้ารหัส URL แปลงอักขระที่ไม่ใช่ ASCII เป็นรูปแบบที่สามารถส่งผ่านทางอินเทอร์เน็ต
การเข้ารหัส URL จะแทนที่อักขระที่ไม่ใช่ ASCII ด้วย "%" ตามด้วยตัวเลขฐานสิบหก
URL ต้องไม่มีช่องว่าง การเข้ารหัส URL ปกติจะแทนที่ช่องว่างที่มีเครื่องหมายบวก (+) หรือ% 20
ตัวอย่างการเข้ารหัส ASCII
เบราเซอร์ของคุณจะเข้ารหัสข้อมูลตามชุดอักขระที่ใช้ในเพจของคุณ
ชุดอักขระที่เป็นค่าเริ่มต้นใน HTML5 คือ UTF-8

สำหรับข้อมูลอ้างอิงทั้งหมดของการเข้ารหัส URL โปรดไปที่การอ้างอิงการเข้ารหัส URL ของเรา
HTML และ XHTML
XHTML เป็น HTML ที่เขียนเป็น XMLXHTML คืออะไร?
- XHTML ย่อมาจาก EXTENSIVE HyperText Markup Language
- XHTML เกือบจะเหมือนกันกับ HTML
- XHTML เข้มกว่า HTML
- XHTML เป็น HTML ที่กำหนดเป็นแอ็พพลิเคชัน XML
- XHTML สนับสนุนโดยเบราว์เซอร์หลัก ๆ ทั้งหมด
ทำไมต้อง XHTML?
หลายหน้าบนอินเทอร์เน็ตมี HTML "ไม่ดี"โค้ด HTML นี้ทำงานได้ดีในเบราว์เซอร์ส่วนใหญ่ (แม้ว่าจะไม่เป็นไปตามกฎ HTML):
<html>
<head>
<title>This is bad HTML</title>
<body>
<h1>Bad HTML
<p>This is a paragraph
</body>
ตลาดวันนี้ประกอบด้วยเทคโนโลยีเบราว์เซอร์ที่แตกต่างกัน เบราว์เซอร์บางรุ่นจะทำงานบนคอมพิวเตอร์และเบราว์เซอร์บางรุ่นจะทำงานบนโทรศัพท์มือถือหรืออุปกรณ์ขนาดเล็กอื่น ๆ อุปกรณ์ขนาดเล็กมักไม่มีทรัพยากรหรือมีอำนาจในการตีความมาร์กอัป "ไม่ดี"
XML เป็นภาษามาร์คอัปที่ต้องมีการทำเครื่องหมายเอกสารอย่างถูกต้อง (เป็น "well-formed")
หากต้องการศึกษา XML โปรดอ่านบทแนะนำ XML ของเรา
โดยการรวมจุดแข็งของ HTML และ XML แล้ว XHTML ได้รับการพัฒนา
XHTML เป็น HTML ที่ออกแบบใหม่เป็น XML
ความแตกต่างที่สำคัญที่สุดจาก HTML:
โครงสร้างเอกสาร
- XHTML DOCTYPE เป็นข้อบังคับ
- แอตทริบิวต์ xmlns ใน <html> เป็นข้อบังคับ
- <html>, <head>, <title> และ <body> มีผลบังคับใช้
องค์ประกอบ XHTML
- องค์ประกอบ XHTML ต้องถูกซ้อนกันอย่างถูกต้อง
- ต้องปิดองค์ประกอบ XHTML เสมอ
- องค์ประกอบ XHTML ต้องเป็นตัวพิมพ์เล็ก
- เอกสาร XHTML ต้องมีองค์ประกอบรากอย่างหนึ่ง
XHTML Attributes
- ชื่อแอตทริบิวต์ต้องเป็นตัวพิมพ์เล็ก
- ต้องระบุค่าแอตทริบิวต์
- การลดแอตทริบิวต์เป็นสิ่งต้องห้าม
<! DOCTYPE .... > เป็นข้อบังคับ
เอกสาร XHTML ต้องมีการประกาศ XHTML DOCTYPE
รายชื่อทั้งหมดของ XHTML Doctypes สามารถดูได้ที่ HTML Tags Reference
ต้องมีองค์ประกอบ
<html>, <head>, <title> และ <body>
และแอตทริบิวต์ xmlns ใน <html> ต้องระบุเนมสเปซ XML สำหรับเอกสาร
ตัวอย่างนี้แสดงเอกสาร XHTML ที่มีแท็กที่ต้องการขั้นต่ำ:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Title of document</title>
</head>
<body>
some content
</body>
</html>
องค์ประกอบ XHTML ต้องถูกซ้อนกันอย่างถูกต้อง
ใน HTML องค์ประกอบบางอย่างอาจซ้อนกันไม่ถูกต้องภายในกันเช่นนี้
<b><i>This text is bold and italic</b></i>
ใน XHTML องค์ประกอบทั้งหมดต้องถูกซ้อนกันอย่างถูกต้องภายในกันเช่นนี้:
<b><i>This text is bold and italic</i></b>
องค์ประกอบ XHTML ต้องปิดเสมอ
นี่เป็นข้อผิดพลาด:
<p>This is a paragraph
<p>This is another paragraph
<p>This is another paragraph
นี้ถูกต้อง:
<p>This is a paragraph</p>
<p>This is another paragraph</p>
องค์ประกอบที่ว่างเปล่าต้องถูกปิด
นี่เป็นข้อผิดพลาด:
A break: <br>
A horizontal rule: <hr>
An image: <img src="happy.gif" alt="Happy face">
A horizontal rule: <hr>
An image: <img src="happy.gif" alt="Happy face">
นี้ถูกต้อง:
A break: <br />
A horizontal rule: <hr />
An image: <img src="happy.gif" alt="Happy face" />
A horizontal rule: <hr />
An image: <img src="happy.gif" alt="Happy face" />
องค์ประกอบ XHTML ต้องอยู่ในตัวพิมพ์เล็ก
นี่เป็นข้อผิดพลาด:
<BODY>
<P>This is a paragraph</P>
</BODY>
<P>This is a paragraph</P>
</BODY>
นี้ถูกต้อง:
<body>
<p>This is a paragraph</p>
</body>
<p>This is a paragraph</p>
</body>
ชื่อแอตทริบิวต์ XHTML ต้องอยู่ในตัวพิมพ์เล็ก
นี่เป็นข้อผิดพลาด:
<table WIDTH="100%">
นี้ถูกต้อง:
<table width="100%">
ต้องมีค่าแอตทริบิวต์
นี่เป็นข้อผิดพลาด:
<table width=100%>
นี้ถูกต้อง:
<table width="100%">
การลดค่าแอตทริบิวต์เป็นสิ่งต้องห้าม
ไม่ถูกต้อง:
<input type="checkbox" name="vehicle" value="car" checked />
แก้ไข:
<input type="checkbox" name="vehicle" value="car" checked="checked" />
ไม่ถูกต้อง:
<input type="text" name="lastname" disabled />
แก้ไข:
<input type="text" name="lastname" disabled="disabled" />
วิธีการแปลงจาก HTML เป็น XHTML
- เพิ่ม XHTML <! DOCTYPE> ลงในบรรทัดแรกของทุกหน้า
- เพิ่มแอตทริบิวต์ xmlns ลงในองค์ประกอบ html ของทุกหน้า
- เปลี่ยนชื่อองค์ประกอบทั้งหมดเป็นตัวพิมพ์เล็ก
- ปิดองค์ประกอบที่ว่างเปล่าทั้งหมด
- เปลี่ยนชื่อแอตทริบิวต์ทั้งหมดเป็นตัวพิมพ์เล็ก
- อ้างค่าแอตทริบิวต์ทั้งหมด




ไม่มีความคิดเห็น:
แสดงความคิดเห็น
หมายเหตุ: มีเพียงสมาชิกของบล็อกนี้เท่านั้นที่สามารถแสดงความคิดเห็น